原文:https://hackernoon.com/showdown-mysql-8-vs-postgresql-10-3fe23be5c19e
链接:https://www.oschina.net/translate/showdown-mysql-8-vs-postgresql-10
译者:雪落无痕xdj, 无若, LinuxTech, Tocy, kevinlinkai
既然 MySQL 8 和 PostgreSQL 10 已经发布了,现在是时候回顾一下这两大开源关系型数据库是如何彼此竞争的。
在这些版本之前,人们普遍认为,Postgres 在功能集表现更出色,也因其 “学院派” 风格而备受称赞,MySQL 则更善长大规模并发读 / 写。
但是随着它们最新版本的发布,两者之间的差距明显变小了。
特性比较
让我们来看看我们都喜欢谈论的 “时髦” 功能。
| 特性 | MySQL 8 | PostgreSQL 10 |
|---|---|---|
| < 查询 & 分析 > | ||
| 公用表表达式 (CTEs) | ✔ New | ✔ |
| 窗口函数 | ✔ New | ✔ |
| < 数据类型 > | ||
| JSON 支持 | ✔ Improved | ✔ |
| GIS / SRS | ✔ Improved | ✔ |
| 全文检索 | ✔ | ✔ |
| < 可扩展性 > | ||
| 逻辑复制 | ✔ | ✔ New |
| 半同步复制 | ✔ | ✔ New |
| 声明式分区 | ✔ | ✔ New |
过去经常会说 MySQL 最适合在线事务,PostgreSQL 最适合分析流程。但现在不是了。
公共表表达式 (CTEs) 和窗口函数是选择 PostgreSQL 的主要原因。但是现在,通过引用同一个表中的 boss_id 来递归地遍历一张雇员表,或者在一个排序的结果中找到一个中值(或 50%),这在 MySQL 上不再是问题。
在 PostgreSQL 中进行复制缺乏配置灵活性,这就是 Uber 转向 MySQL 的原因。但是现在,有了逻辑复制特性,就可以通过创建一个新版本的 Postgres 并切换到它来实现零停机升级。在一个巨大的时间序列事件表中截断一个陈旧的分区也要容易得多。
就特性而言,这两个数据库现在都是一致的。
有哪些不同之处呢?
现在,我们只剩下一个问题 —— 那么,选择一个而不选另一个的原因是什么呢?
生态系统是其中一个因素。MySQL 有一个充满活力的生态系统,包括 MariaDB、Percona、Galera 等等,以及除 InnoDB 以外的存储引擎,但这也可能是和令人困惑的。Postgres 的高端选择有限,但随着最新版本引入的新功能,这会有所改变。
治理是另一个因素。当 Oracle(或最初的 SUN)收购 MySQL 时,每个人都担心他们会毁掉这个产品,但在过去的十年里,这并不是事实。事实上,在收购之后,发展反倒加速了。而 Postgres 在工作管理和协作社区方面有着丰富的经验。
基础架构不会经常改变,虽然近来没有对这方面的详细讨论,这也是值得再次考虑的。
来复习下:
| 特性 | MySQL 8 | PostgreSQL 10 |
|---|---|---|
| 架构 | 单进程 | 多进程 |
| 并发 | 多线程 | fork(2) |
| 表结构 | 聚簇索引 | 堆 |
| 页压缩 | Transparent | TOAST |
| 更新 | In-Place / Rollback Segments | Append Only / HOT |
| 垃圾回收 | 清除线程 | 自动清空进程 |
| 事务日志 | REDO Log (WAL) | WAL |
| 复制日志 | Separate (Binlog) | WAL |
进程 vs 线程
当 Postgres 派生出一个子进程来建立连接时,每个连接最多可以占用 10MB。与 MySQL 的线程连接模型相比,它的内存压力更大,在 64 位平台上,线程的默认堆栈大小为 256KB。(当然,线程本地排序缓冲区等使这种开销变得不那么重要,即使在不可以忽略的情况下,仍然如此。)
尽管 “写时复制” 保存了一些与父进程共享的、不可变的内存状态,但是当您有 1000 多个并发连接时,基于流程的架构的基本开销是很繁重的,而且它可能是容量规划的最重要的因素之一。
也就是说,如果你在 30 台服务器上运行一个 Rails 应用,每个服务器都有 16 个 CPU 核心 32 线程,那么你有 960 个连接。可能只有不到 0.1% 的应用会超出这个范围,但这是需要记住的。
聚簇索引 vs 堆表
聚簇索引是一种表结构,其中的行直接嵌入其主键的 b 树结构中。一个(非聚集)堆是一个常规的表结构,它与索引分别填充数据行。
有了聚簇索引,当您通过主键查找记录时,单次 I/O 就可以检索到整行,而非集群则总是需要查找引用,至少需要两次 I/O。由于外键引用和 JOIN 将触发主键查找,所以影响可能非常大,这将导致大量查询。
聚簇索引的一个理论上的缺点是,当您使用二级索引进行查询时,它需要遍历两倍的树节点,第一次扫描二级索引,然后遍历聚集索引,这也是一棵树。
但是,如果按照现代表设计的约定,将一个自动增量整数作为主键 [1]——它被称为代理键——那么拥有一个聚集索引几乎总是可取的。更重要的是,如果您做了大量的 ORDER BY id 来检索最近的(或最老的)N 个记录的操作,我认为这是很适用的。
Postgres 不支持聚集索引,而 MySQL(InnoDB) 不支持堆。但不管怎样,如果你有大量的内存,差别应该是很小的。
页结构和压缩
Postgres 和 MySQL 都有基于页面的物理存储。(8KB vs 16KB)
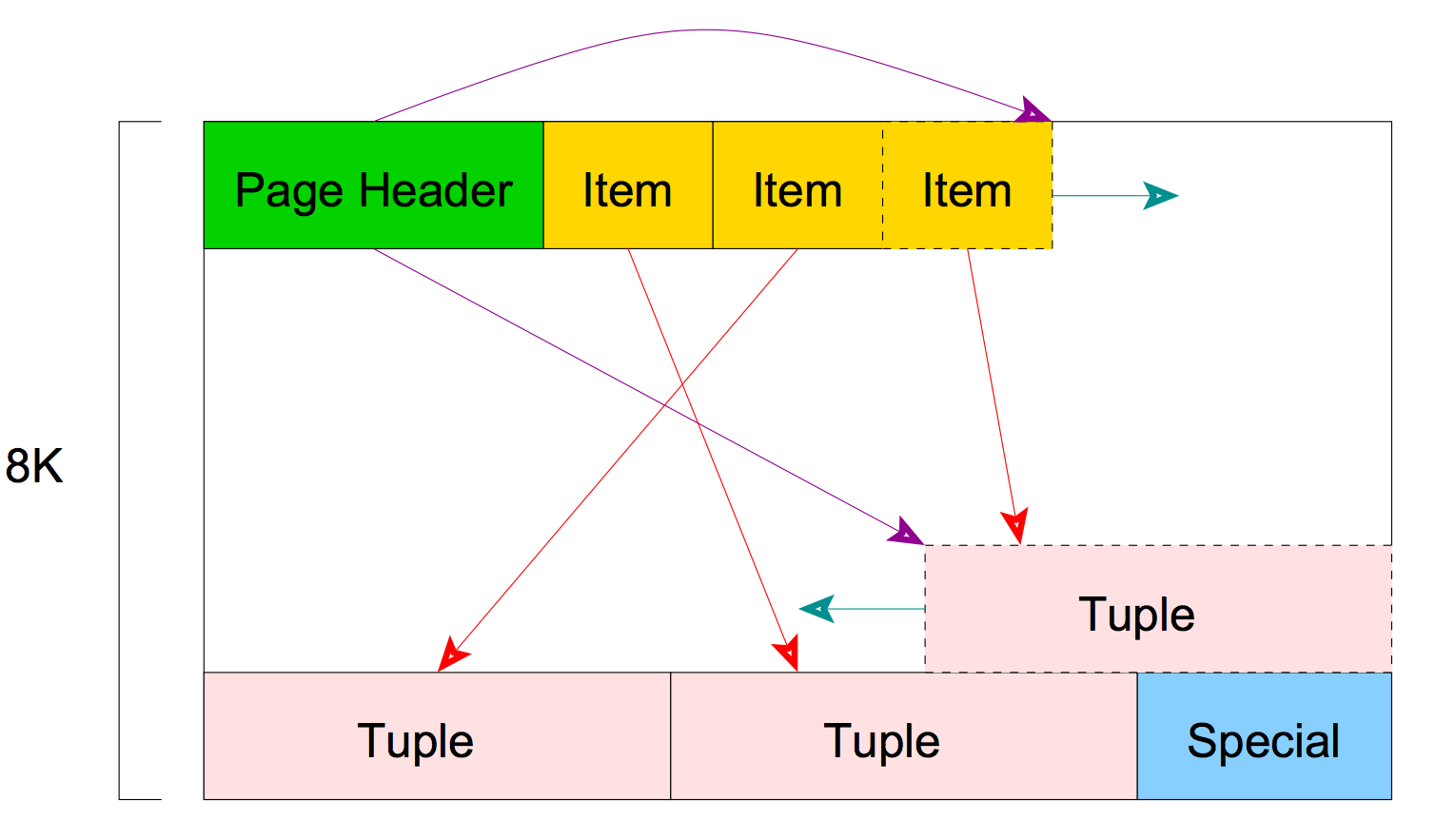
页结构看起来就像右边的图。它包含一些我们不打算在这里讨论的条目,但是它们包含关于页的元数据。条目后面的项是一个数组标识符,由指向元组或数据行的(偏移、长度)对组成。在 Postgres 中,相同记录的多个版本可以以这种方式存储在同一页面中。
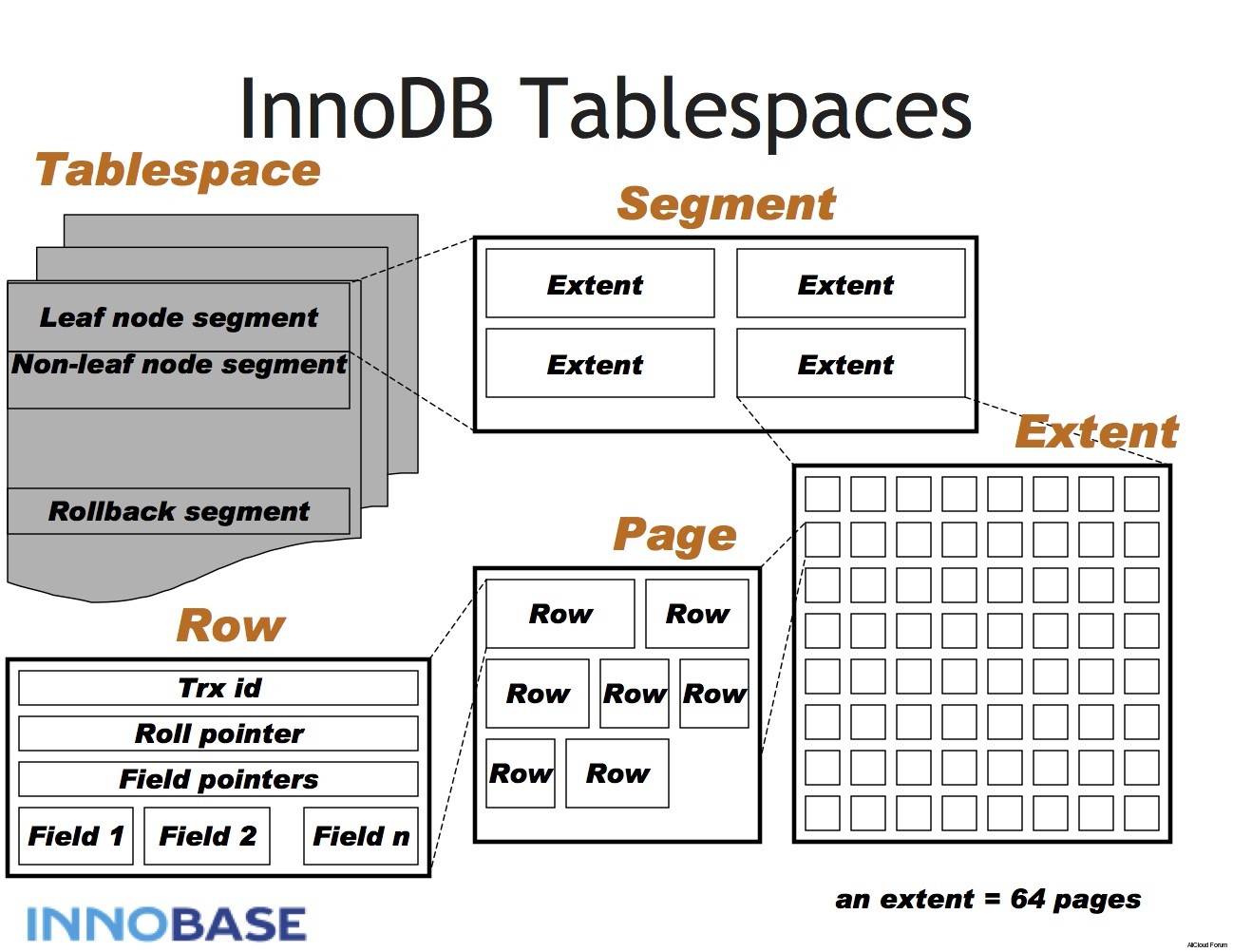
MySQL 的表空间结构与 Oracle 相似,它有多个层次,包括层、区段、页面和行层。
此外,它还有一个用于撤销的单独段,称为 “回滚段”。与 Postgres 不同的是,MySQL 将在一个单独的区域中保存同一记录的多个版本。
如果存在一行必须适合两个数据库的单个页面,,这意味着一行必须小于 8KB。(至少有 2 行必须适合 MySQL 的页面,恰巧是 16KB/2 = 8KB)
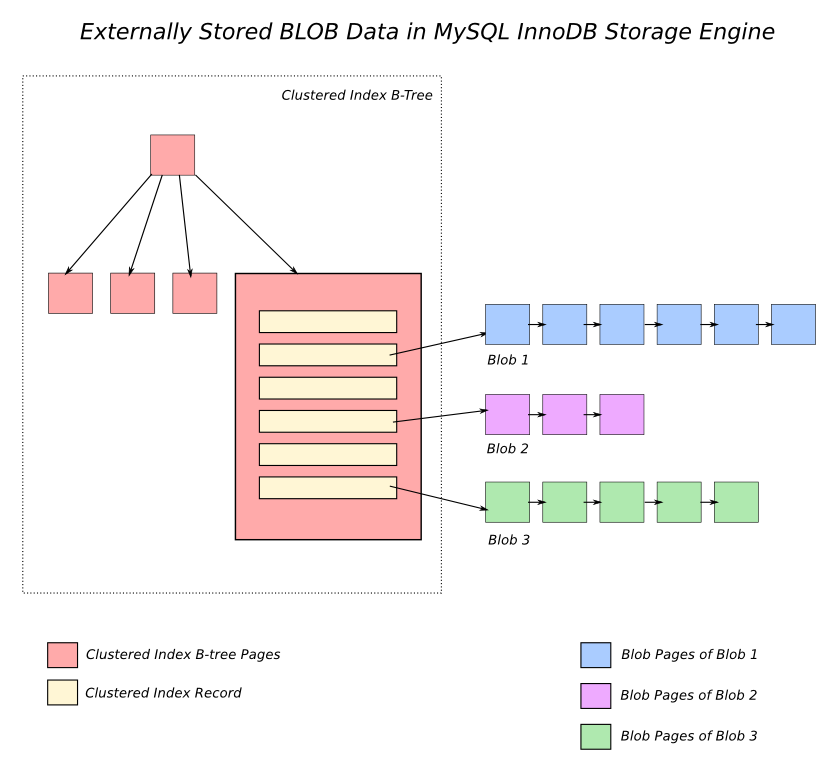
那么当你在一个列中有一个大型 JSON 对象时会发生什么呢?
Postgres 使用 TOAST,这是一个专用的影子表 (shadow table) 存储。当行和列被选中时,大型对象就会被拉出。换句话说,大量的黑盒不会污染你宝贵的缓存。它还支持对 TOAST 对象的压缩。
MySQL 有一个更复杂的特性,叫做透明页压缩,这要归功于高端 SSD 存储供应商 Fusio-io 的贡献。它设计目的是为了更好地使用 SSD,在 SSD 中,写入量与设备的寿命直接相关。
对 MySQL 的压缩不仅适用于页面外的大型对象,而且适用于所有页面。它通过在稀疏文件中使用打孔来实现这一点,这是被 ext4 或 btrfs 等现代文件系统支持的。
有关更多细节,请参见:在 FusionIO 上使用新 MariaDB 页压缩获得显著的性能提升。
更新的开销
另一个经常被忽略的特性,但是对性能有很大的影响,并且可能是最具争议的话题,是更新。
这也是 Uber 放弃 Postgres 的另一个原因,这激起了许多 Postgres 的支持者来反驳它。
MySQL 对 Uber
可能是合适的, 但是未必对你合适
两者都是 MVCC 数据库,它们可以隔离多个版本的数据。
为了做到这一点,Postgres 将旧数据保存在堆中,直到被清空,而 MySQL 将旧数据移动到一个名为回滚段的单独区域。
在 Postgres 中,当您尝试更新时,整个行必须被复制,以及指向它的索引条目也被复制。这在一定程度上是因为 Postgres 不支持聚集索引,所以从索引中引用的一行的物理位置不是由逻辑键抽象出来的。
为了解决这个问题,Postgres 使用了堆上元组(HOT),在可能的情况下不更新索引。但是,如果更新足够频繁(或者如果一个元组比较大),元组的历史可以很容易地超过 8 KB 的页面大小,跨越多个页面并限制该特性的有效性。修剪和 / 或碎片整理的时间取决于启发式解决方案。另外,设置不超过 100 的填充参数会降低空间效率——这是一种很难在创建表时考虑的折衷方案。
这种限制更深入; 因为索引元组没有关于事务的任何信息,所以直到 9.2 之前一直不能支持仅索引扫描。 它是所有主要数据库(包括 MySQL,Oracle,IBM DB2 和 Microsoft SQL Server)支持的最古老,最重要的优化方法之一。 但即使使用最新版本,当有许多 UPDATE 在可见性映射中设置脏位时,Postgres 也不能完全支持仅索引扫描,并且在我们不需要时经常选择 Seq 扫描。
在 MySQL 上,更新发生在原地,旧的行数据被封存在一个称为回滚段的独立区域中。 结果是你不需要 VACUUM,并且提交非常快,而回滚相对较慢,这对于大多数用例来说是一个可取的折衷。
它也足够聪明,尽快清除历史。 如果事务的隔离级别设置为 READ-COMMITTED 或更低,则在语句完成时清除历史记录。
事务记录的大小不会影响主页面。 碎片化是一个伪命题。 因此,在 MySQL 上能更好,更可预测整体性能。
Garbage Collection 垃圾回收
在 Postgres 中 VACUUM 上开销很高,因为它在主要工作在堆区,造成了直接的资源竞争。它感觉就像是编程语言中的垃圾回收 - 它会挡在路上,并随时让你停下来。
为具有数十亿记录的表配置 autovacuum 仍然是一项挑战。
在 MySQL 上清除(Purge)也可能相当繁重,但由于它是在单独的回滚段中使用专用线程运行的,因此它不会以任何方式影响读取的并发性。即使使用默认配置,变膨胀的回滚段使你执行速度减慢的可能性也是很低的。
拥有数十亿记录的繁忙表不会导致 MySQL 上的历史数据膨胀,诸如存储上的文件大小和查询性能等事情上几乎是可以预测的并且很稳定。