1、概述
前两遍文章中,我们一直在说后文要介绍 Nginx + Keepalived 的搭建方式。这篇文章开始,我们就来兑现前文的承诺,后续的两篇文章我们将介绍 Nginx + Keepalived 和 LVS + Keepalived 搭建高可用的负载层系统。如果你还不了解 Nginx 和 LVS 的相关知识,请参见我之前的两篇文章《架构设计:负载均衡层设计方案(2)——Nginx 安装》(http://blog.csdn.net/yinwenjie/article/details/46620711)、《架构设计:负载均衡层设计方案(4)——LVS 原理》(http://blog.csdn.net/yinwenjie/article/details/46845997)
2、准备工作
2.1、准备两台独立工作的 Nginx 系统
准备两台 Nginx 的主机,如果您不知道为什么需要准备两台,没关系,准备就行。保证两台 Nginx 主机能够被外网访问。在我这里,安装两台 Nginx 的虚拟机 IP 地址分别是:
- Nginx VM1:192.168.61.129:80
- Nginx VM2:192.168.61.130:80
访问相关的地址,确保两台 Nginx 都是可用的:
VM1:
VM2:
Nginx 的安装在我的前文《架构设计:负载均衡层设计方案(2)——Nginx 安装》(http://blog.csdn.net/yinwenjie/article/details/46620711)中已经进行了详细的讲解,所以这里的讲解就一笔带过。
2.2、再分别独立安装 Keepalived 系统
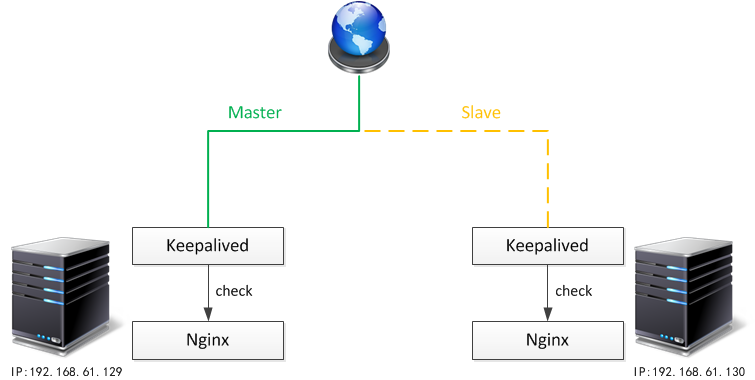
我们的目标是 “在一台工作的 Nginx 崩溃的情况下,系统能够检测到,并自动将请求切换到另外一台备份的 Nginx 服务器上”。所以,之前安装的两台 Nginx,一台是 Master 服务器是主要的工作服务器,另一台是备份服务器,在 Master 服务器出现问题后,由后者接替其工作。如下图所示(外网的请求使用一个由 keepalived 控制的虚拟的浮动 IP 进行访问):
请到 www.keepalived.org 下载 keepalived 的稳定版本,我下载的是 1.2.17 版本。
解压,并且安装。注意,我在这里制定了 perfix 参数,指定安装位置,这是为了我自己便于管理。您在安装的时候,可以根据自己的情况来决定是不是加这个参数:
tar -zxvf keepalived-1.2.17.tar.gz ./configure --perfix=/usr/keepalived-1.2.17 make & make install如果您不是安装到默认路径,那么为了将 keepalived 做成系统服务,您需要拷贝一些文件到指定的路径下,如下:
cp /usr/keepalived-1.2.17/etc/sysconfig/keepalived /etc/sysconfig/keepalived cp /usr/keepalived-1.2.17/sbin/keepalived /usr/sbin/keepalived cp /usr/keepalived-1.2.17/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/keepalived mkdir /etc/keepalived cp /usr/keepalived-1.2.17/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf然后您可以将 keepalived 做成服务了:
/etc/rc.d/init.d/keepalived chkconfig keepalived on
3、检查 Nginx 状态
在正式介绍 Nginx + Keepalived 的配置前,我们首先介绍一下如何检查 Nginx 的状态。是的,这是为下一小节做准备。我们只有能够正确检查 Nginx 的状态,才说得上在 Nginx 节点出现问题的情况下,切换到另一台 Nginx 上接替其工作。
Nginx 为什么会停止响应呢?在我的工作经验中,无非有以下几种情况:
Nginx 的所有进程被强行终止(或管理进程)。
这种情况,是我们需要检查和切换的。无论什么情况下进程被终止了,如果它不能重启,我们就要切换到备机。Nginx 日志盘的挂载点崩溃或者磁盘写满。
这个也是我们需要检查和切换的。Nginx 已经达到设置的最大连接数,暂时停止响应。
这种情况下,我们不能进行备机切换,因为通过 VIP:192.168.61.100 连接过来的用户请求比较多(在我们优化参数后,可以达到 65535 / 4 的数量),一旦我们进行备机切换,这些用户请求将全部异常。这个问题的解决需要靠增加负载机器,而不是主备切换。Nginx 物理机异常关机。
这个肯定是需要进行检查和切换的。
我们来看一段 Linux 脚本:
#!/bin/sh
if [ $(ps -C nginx --no-header | wc -l) -eq 0 ]; then
/usr/nginx-1.6.2/sbin/nginx
fi
sleep 2
if [ $(ps -C nginx --no-header | wc -l) -eq 0 ]; then
service keepalived stop
fi
我们大致讲解一下 “ps -C nginx –no-header | wc -l” 这个命令:
- ps 这个命令用来进行 Linux 中进程相关的查询,-C 意思是按照进程名称进行查询。查询出来后的结果如下:
[root@vm2 ~]# ps -C nginx
PID TTY TIME CMD
3374 ? 00:00:00 nginx
3375 ? 00:00:01 nginx
如果要去掉统计出来的结果表的头部,那么要使用 –no-header 参数,加上参数后,查询结果如下:
[root@vm2 ~]# ps -C nginx --no-header 3374 ? 00:00:00 nginx 3375 ? 00:00:01 nginx“|”,这是 Linux 中的管道流命令,将上一个命令的输出结果作为下一个命令的输入。
wc 统计命令,-l 参数,代表按行数进行统计。所以整个命令的输出结果为:
[root@vm2 ~]# ps -C nginx --no-header | wc -l 2
清楚了其中最关键的命令,我们再来讲解一下整个脚本的含义:
第一个判断说明的是,如果当前 nginx 的进程数量 == 0,那么执行 nginx 的启动命令,试图重新启动 nginx;接下来等待 2 秒(这是为了给 nginx 一定的启动时间),然后再次查看 Nginx 的进程数量,如果仍然 == 0,那么停止这台机器的 keepalived 服务,以便备用的 Keepalived 节点检查到 Keepalived 已经停止这个事件,并将浮动 IP 切换到备用服务器上。
注意,这段脚本是和我机器上的 Nginx 安装路径、Keepalived 服务的状态有关的,您如果要用的话,请进行相应的更改。
4、Nginx + Keepalived 最简配置
4.1、请再次确认前提
(首先,为了保证不会出现额外的问题,请首先关闭防火墙,当然正式环境里面,防火墙不能关闭)
外网进行 Nginx 访问的浮动 IP:192.168.61.100
我们将 192.168.61.129 这台服务器上运行的 Nginx 作为主要的 Nginx,其上的 keepalived 服务我们设置成 Master 方式。
我们将 192.168.61.129 这台服务器上运行的 Nginx 作为备用的 Nginx 服务,其上的 keepalived 服务我们设置为 Backup 方式。
4.2、正式开始设置
注意,经过安装,您的 keepalived 配置文件的位置在 “/etc/keepalived/keepalived.conf”(如果没有,请创建一个,但是经过之前的步骤,这个位置肯定是有文件的,如果没有可能是之前您的步骤出现了什么问题)。
4.2.1、设置 192.168.61.129 上的 MASTER
我们先来看看 192.168.61.129 上的原始 ip 信息:
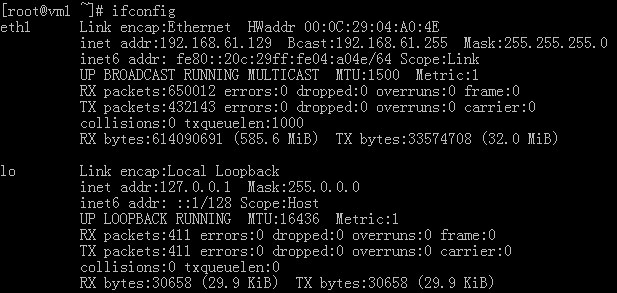
注意,这个 129 机器上的网卡设备号是 eth1,而不是 eth0,这个参数我们将在配置 keepalived 的时候使用到。
下面是 129 上 keepalived 的最简配置:
! Configuration File for keepalived
# global setting , notify email setting
global_defs {
#存在于同一个网段中,一组keepalived的各个节点都有不同的名字
#在全局设置中,我们还可以设置管理员的email信息等。
router_id LVS_V1
}
#这个是我们在上一小结讲到的nginx检查脚本,我们保存在这个文件中(注意文件权限)
vrrp_script chknginx {
script "/usr/keepalived-1.2.17/bin/checknginx.sh"
#每10秒钟,检查一次
interval 10
}
#keepalived实例设置,是最重要的设置信息
vrrp_instance VI_1 {
#state状态MASTER表示是主要工作节点。
#一个keepalived组中,最多只有一个MASTER节点,当然也可以没有
state MASTER
#实例所绑定的网卡设备,我的网卡设备是eth1。您按照您自己的来
interface eth1
#同一个keepalived组,节点的设置必须一样,这样才会被识别
virtual_router_id 52
#节点优先级,BACKUP的优先级一定要比MASTER的优先级低
priority 100
#组播信息发送间隔,两个节点设置必须一样
advert_int 1
#实际的eth1上的固定ip地址
mcast_src_ip=192.168.61.129
#验证信息,只有验证信息相同,才能被加入到一个组中。
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟地址和绑定的端口,如果有多个,就绑定多个
#dev 是指定浮动IP要绑定的网卡设备号
virtual_ipaddress {
192.168.61.100 dev eth1
}
#设置的检查脚本
#关联上方的“vrrp_script chknginx”
track_script {
chknginx
}
}
4.2.2、设置 192.168.61.130 上的 BACKUP
再来看看 192.168.61.130 这个备用节点上 keepalived 的设置:
! Configuration File for keepalived
# global setting , notify email setting
global_defs {
#这里和master节点不同
router_id LVS_V2
}
#check nginx
vrrp_script chknginx {
script "/usr/keepalived-1.2.17/bin/checknginx.sh"
interval 10
}
# instance setting
vrrp_instance VI_1 {
# 这里和Master节点不一样
state BACKUP
interface eth1
# 这里一定是一样的
virtual_router_id 52
# 这里的优先级比Master节点低
priority 99
advert_int 1
# 这里和Master节点不一样
mcast_src_ip=192.168.61.130
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.61.100 dev eth1
}
track_script {
chknginx
}
}
4.3、启动主节点和备用节点
以上配置中请注意几个关键点:
- 注意 nginx 状态检查的脚本的位置,根据自己创建文件的位置不一样,脚本检查的指定位置也不一样
- 注意优先级,MASTER 节点的优先级一定要高于所有的 BACKUP 节点。
- 注意局域网的组播地址,一定要可用。局域网内所有 keepalived 节点都是利用组播方式寻找对方。
- 谁说 BACKUP 节点只能有一个!?
- 最后,keepalived 一定要注册成服务形式,您可以想象上面所有脚本、配置、命令如果重启后再来一次,会是什么情况。
接下来,我们要开始启动 Master 节点和 Backup 节点了,为了准确的查看日志状态,您需要观察系统日志。系统日志所在的位置:
tail -f /var/log/messages
先启动 Master 节点:
service keepalived start
再启动 Backup 节点:
service keepalived start
如果设置和启动都是成功的,您不会在日志信息中收到任何的 keepalived 报错信息。接下来您就可以使用 192.168.61.100 这个 IP 访问 Nginx 了:
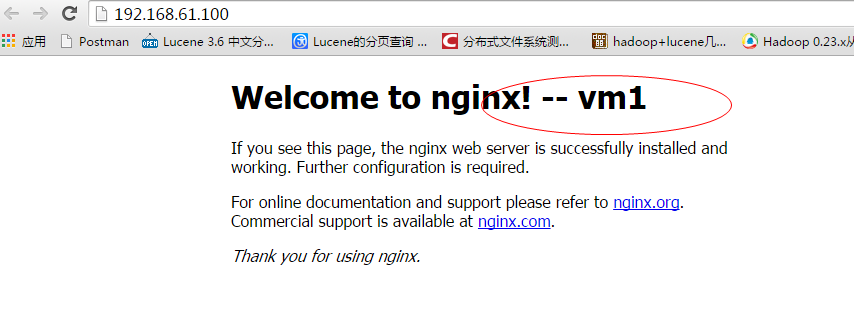
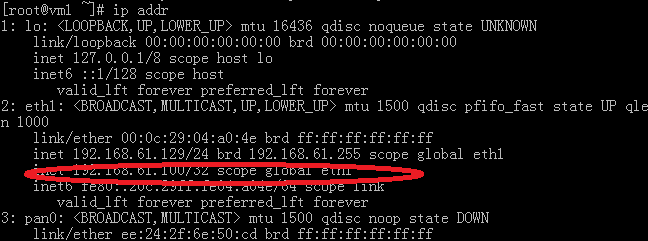
另外,这个绑定在 192.168.61.129 上的浮动 ip:192.168.61.100,您通过 ipconfig 命令一般是看不到的,要使用 ip addr 命令进行查看:
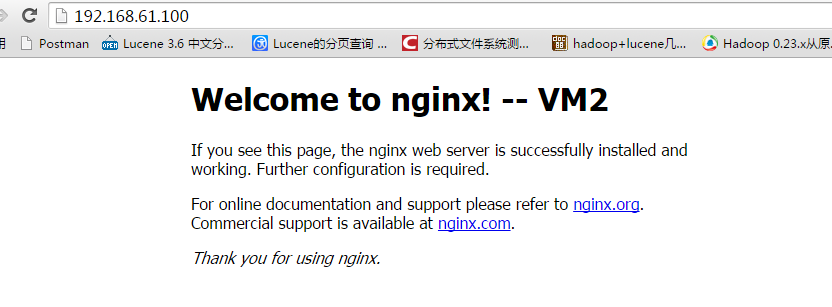
为了试验,我们主动停止 Master 节点上的 keepalived 服务(注意,杀 Nginx 进程不起作用,因为我们的检查脚本会试图重新启动 Nginx 进程),接下来我们可以看到浮动 IP 漂移到了 130 备机上:
5、Nginx + Keepalived 非抢占模式
通过第 4 节的详细介绍,相信您对 Nginx + Keepalived 的安装方式有了一个明确的理解。keepalived 的切换可以是自动的,但是却做不到毫秒级别,他怎么都需要几秒钟的时间进行切换。
这就有一个问题,虽然在主节点出现问题我们转向备份节点时,这个延时无可避免,但是在我们修复主节点后,实际上并没有必要再马上做一次切换,所以 Keepalived 提供了一种非抢占模式,来满足这个要求。
下面我们就来介绍一下 Keepalived 的非抢占模式的配置(无 MASTER 节点,全部依据优先级确定哪个节点进行工作):
5.1、原来主节点的配置改动
! Configuration File for keepalived
# global setting , notify email setting
global_defs {
router_id LVS_V1
}
vrrp_script chknginx {
script "/usr/keepalived-1.2.17/bin/checknginx.sh"
interval 10
# 一旦节点失效,节点的优先级就减少2
# 有多少个keepalived节点,就填写多少数量。
# 这样保证这个节点的优先级比其他节点都低
weight -2
# fall 表示多少次检查失败,就算节点失效。默认1
#fall 1
}
vrrp_instance VI_1 {
#state状态都是BACKUP表示是主要工作节点。
state BACKUP
interface eth1
virtual_router_id 52
# 这个关键配置项,设置为“非抢占”模式
nopreempt
# 每个节点的优先级一定要不一样
priority 100
advert_int 1
mcast_src_ip=192.168.61.129
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟地址和绑定的端口,如果有多个,就绑定多个
#dev 是指定浮动IP要绑定的网卡设备号
virtual_ipaddress {
192.168.61.100 dev eth1
}
#设置的检查脚本
#关联上方的“vrrp_script chknginx”
track_script {
chknginx
}
}
原来的主节点设置更改完成。
5.2、原来备份节点的配置改动
加入 “非抢占” 模式的关键字、更改一个确定的优先级,设置检查失败后优先级的递减量,就行了。
6、后文介绍
这是我 8 月份的首篇文章,后文我们将介绍 LVS + Keepalived + Nginx 的安装和配置方式。注意,LVS 被 Keepalived 后,就没有必要在对 Nginx 做 Keepalived 了。