hbase 是强一致性的海量数据库,无论是读写性能,或是数据容量,还是一致性方面,hbase 都有非常优秀的表现。
本文从架构方面探讨 hbase 的主要设计,从而在需要 hbase 的场合能够更好的设计和判断。
首先,先来看看 hbase 的整体架构。除了 DFS 组件,hbase 的基本组件图实际上就是 Zookeeper,HMaster,RegionServer。
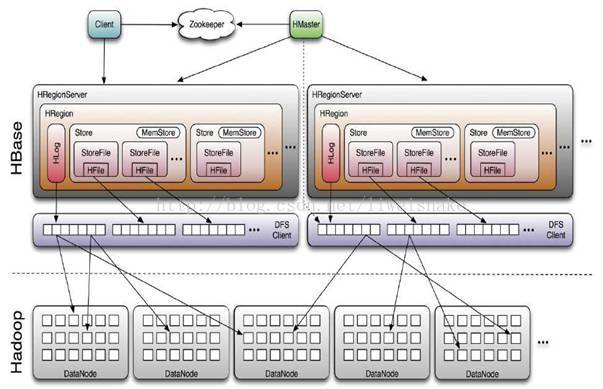
其中,RegionServer 作为数据的实际存取服务器,主要负责数据的最终存取,一般情况都是多台;
RegionServer 根据不同的 row key 划分为许多 region,每个 region 按顺序存放从 startKey 到 endKey 的数据。每个 RegionServer 有下面这些组件:
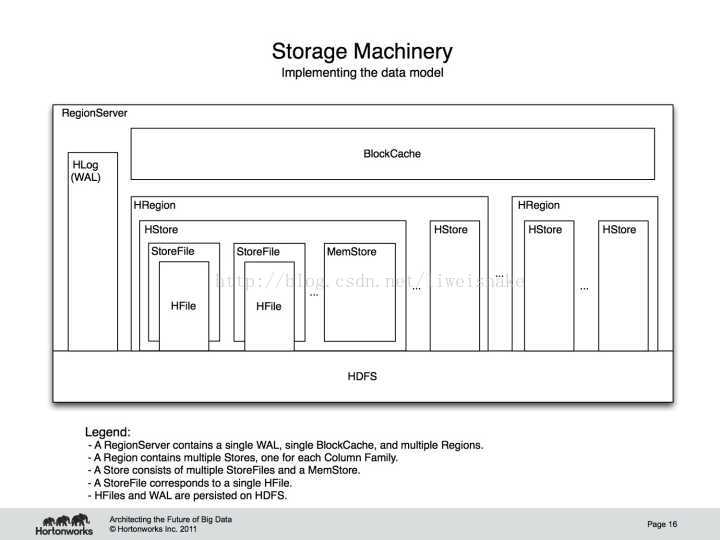
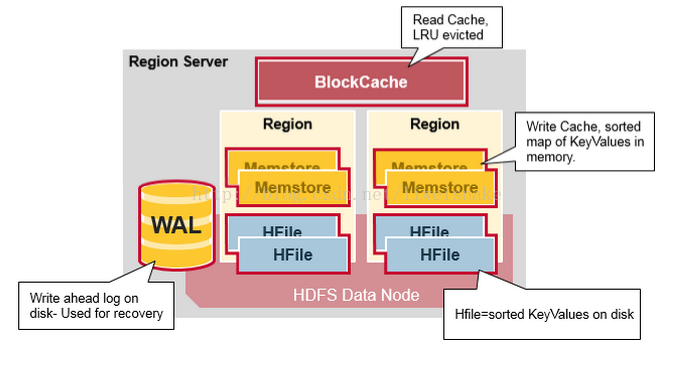
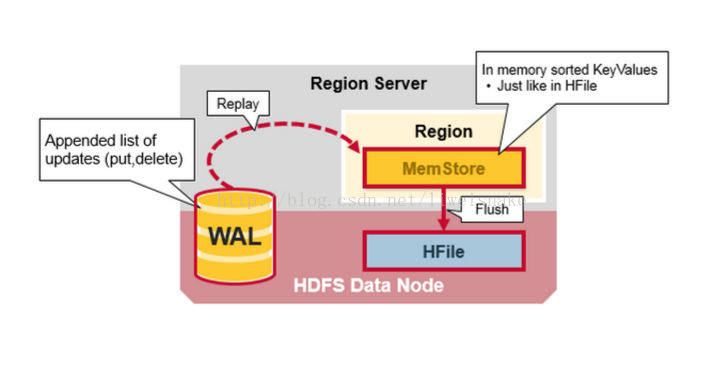
一个 WAL: write ahead log. 听名知其意,该文件是落库前先写的日志文件,它最主要的作用是恢复数据用,类似于 mysql 的 binlog。保存在 HDFS 中
一个 BlockCache: regionServer 的读缓存。保存使用最频繁的数据,使用 LRU 算法换出不需要的数据。
多个 Region: 每个 region 包含多个 store,每个 CF 拥有一个 store
store: 每个 store 包含多个 storeFile 和一个 memstore
Memstore: region 的写缓存。保存还未写入 HFile 的数据,写入数据前会先做排序,每个 region 每个 CF 都会拥有一个 Memstore,这就是为什么 CF 不能建太多的原因。
storeFile: 真正存储 keyvalue 数据的文件,其保存的文件是排序过的。一个 storeFile 对应一个 HFile。保存在 HDFS 中
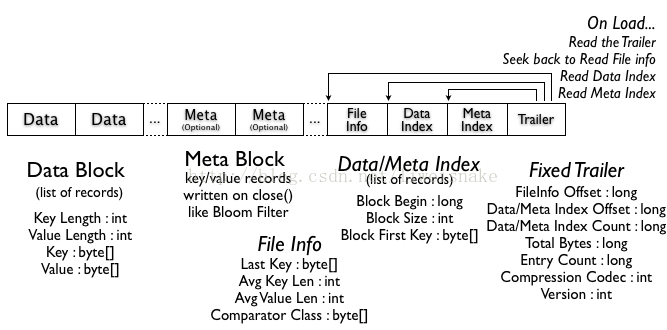
HFile 分为数据块,索引块,bloom 过滤器以及 trailer。
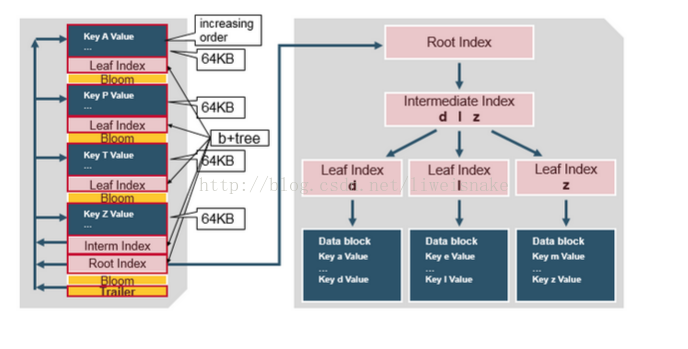
Trailer 主要记录了 HFile 的基本信息,各个部分的偏移和地址信息。
Data block 主要存储用户的 key-value 数据
Bloom filter 主要用来快速定位文件是否不在数据块。

比较容易混淆的是 zookeeper 和 hmaster。
Zookeeper 负责保持多台 Hmaster 中只有一台是活跃的;存储 Hbase 的 schema,table,CF 等元信息;存储所有的 region 入口;监控 regionServer 的状态,并将该信息通知 hmaster。可以看出来,zookeeper 几乎是负责整个集群的关键信息存取以及关键状态监控。如果 zookeeper 挂了,那么整个 hbase 集群几乎就是不可用的状态。
Hmaster 则是负责对 table 元数据的管理;对 HRegion 的负载均衡,调整 HRegion 的布局,比如分裂和合并;包括恢复数据的迁移等。Hmaster 相当于对 RegionServer 的后台管理,对于一些定制的管理行为,zookeeper 不可能帮你完成,于是乎才有了 hmaster。如果 hmaster 挂了,除了不能对 table 进行管理配置,不能扩展 region,并不会影响整体服务的可用性。
接下来我们来关注一些关键流程。
客户端首次读写的流程:
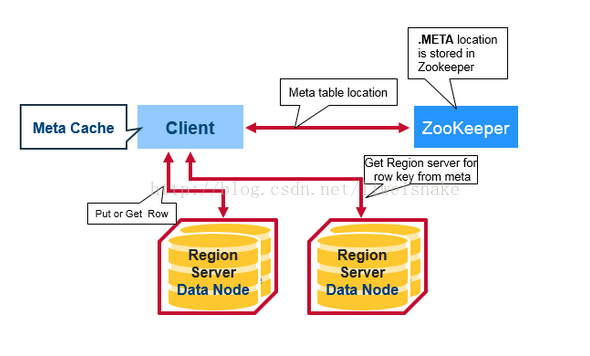
1. 客户端首先从 zookeeper 中得到 META table 的位置,根据 META table 的存储位置得到具体的 RegionServer 是哪台
2. 询问具体的 RegionServer
写流程:
1. 首先写入 WAL 日志,以防 crash。
2. 紧接着写入 Memstore,即写缓存。由于是内存写入,速度较快。
3. 立马返回客户端表示写入完毕。
4. 当 Memstore 满时,从 Memstore 刷新到 HFile,磁盘的顺序写速度非常快,并记录下最后一次最高的 sequence 号。这样系统能知道哪些记录已经持久化,哪些没有。
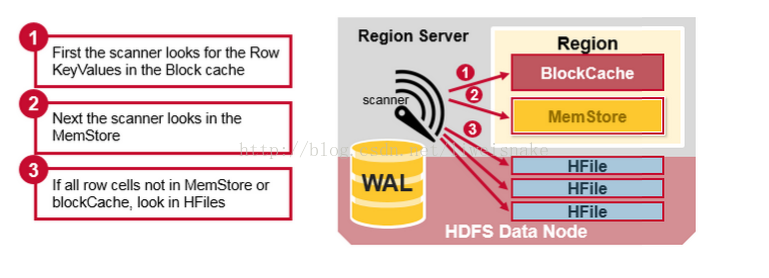
读流程:
1. 首先到读缓存 BlockCache 中查找可能被缓存的数据
2. 如果未找到,到写缓存查找已提交但是未落 HFile 的数据
3. 如果还未找到, 到 HFile 中继续查找数据
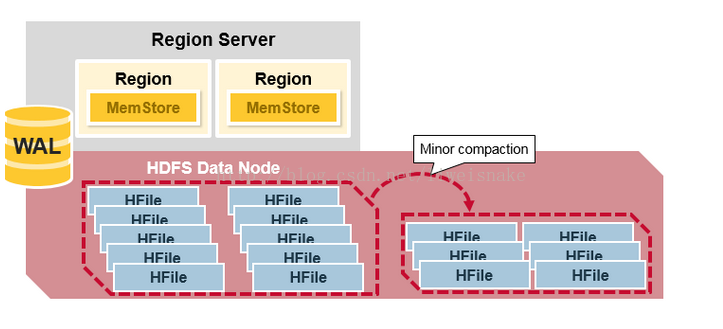
数据紧凑:
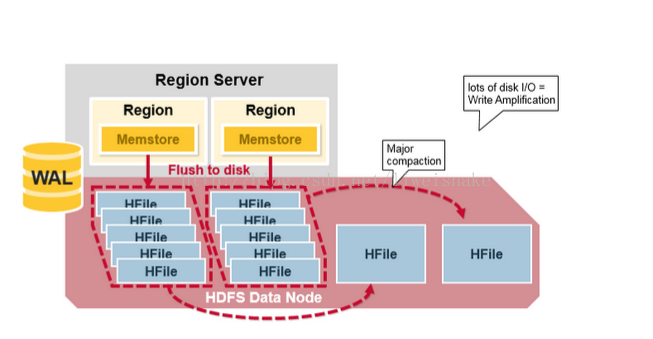
数据从 memStore 刷新到 HFile 时,为了保持简单,都是每个 memStore 放一个 HFile,这会带来大量小 HFile 文件,使得查询时效率相对较低,于是,采用数据紧凑的方式将多个小文件压缩为几个大文件。其中,minor compaction 是自动将相关的小文件做一些适当的紧凑,但不彻底;而 major compaction 则是放在午夜跑的定时任务,将文件做最大化的紧凑。
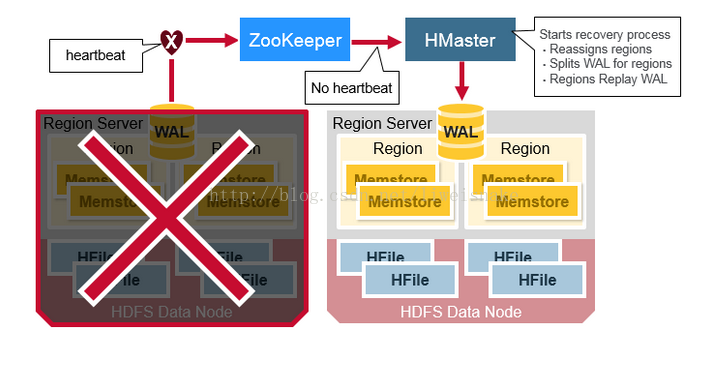
数据恢复流程:
当 RegionServer 挂了,zookeeper 很快就能检测到,于是将其下的 region 状态设置为不可用。Hmaster 随即开始恢复的流程。
1. HFile 本身有 2 个备份,而且有专门的 HDFS 来管理其下的文件。因此对 HFile 来说并不需要恢复。
2. Hmaster 重置 region 到新的 regionServer
3. 之前在 MemStore 中丢失的数据,通过 WAL 分裂先将 WAL 按照 region 切分。切分的原因是 WAL 并不区分 region,而是所有 region 的 log 都写入同一个 WAL。
4. 根据 WAL 回放并恢复数据。回放的过程实际上先进 MemStore,再 flush 到 HFile